![]()
Master -
Yucchi
Since - 2012/05/05
Java秘密基地
Java Persistence API で遊ぶ - 3 -
今回は前回までに作成したエンティティクラスを使用し、JPQL(Java Persistence Query Language)を試します。
JPQLとはエンティティクラスのためのデータベースに依存しない言語です。
つまり、データベース専用のSQL文を使わなくていい!
ただし、八方美人的なことを可能にするかわりに一般的に使用される機能の提供だけに留まってます。
どうしてもチューニングされたSQL文を使いたい場合はネイティブクエリが使用できます。
しかし、そのような場合結果セットマッピングを使用することになるでしょうから非常に面倒です。
まぁ、作ってしまえば後はデータベース専用のSQL文が発行可能になります。
とりあえず、JPQLをお気楽に簡単に使って遊んでみましょう。
今回も NetBeans6.0 を使って試してみます。
開発環境は
OS Windows Vista Ultimate 64bit
JDK6u3
NetBeans IDE 6.0
MySQL 5.0.45 (Community 版)
です。
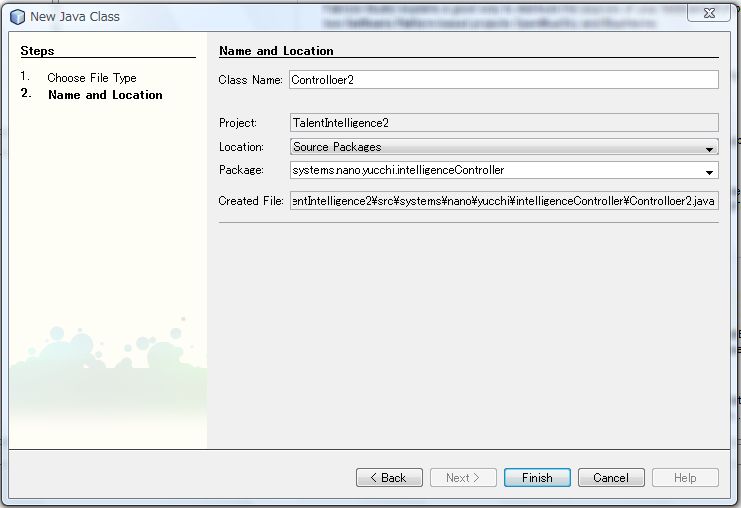
[ TalentIntelligence2 ] → [ New ] → [ Java Class... ] をクリックします。
New Java Class ウィンドウが表示されます。
下図のように設定し、[ Finsh ] をクリックします。
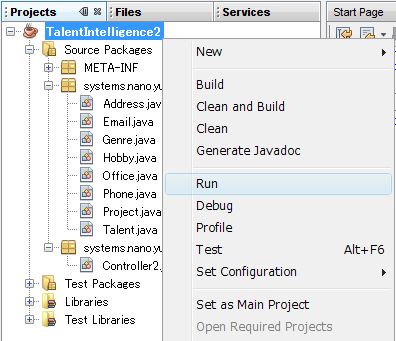
Controller2 クラスが自動生成されますので <Java Persistence API で遊ぶ - 1 - > で作った Contorollerクラスと同様なクラスをつくります。
コードは下記のようになります。
では、ちゃんと動くか確認します。
[ TalentIntelligence2 ] → [ Run ] をクリックして実行します。
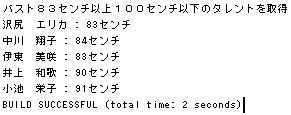
Output ウィンドウにプログラムの実行結果が表示されます。
期待を裏切らない結果がでました(^^)
ちなみに、これらのデータはネット上で拾ったもので本当かどうかは解りません。
次は talent テーブルに登録されているタレントでバストが83センチ以上100センチ以下のタレントを検索します。
WHERE 節 と AND 演算子を使い、設定値をパラメータで渡します。
ちゃんと検索されてます。
今回は設定値をパラメータとして渡しました。
setParameter メソッドを使用すると可能です。
名前で指定する方法と位置で指定する方法があります。
今回は名前で指定する方法を使用しました。
パラメータ名の先頭に " : " をつけます。
そして setParameter メソッドの第一引数に String 型、第二引数は Object 型の値を指定します。
位置で指定するには " ? "と数値を組み合わせて記述します。
そして setParameter メソッドの第一引数に int 型で指定し、第二引数は Object 型の値を指定します。
さて、上のプログラムではちゃんと検索はされましたが表示されている順番を変えたい場合があります。
そこで検索条件にバストが大きい順に表示させるようにしてみましょう。
ORDER BY 節を使うと可能になります。
そして降順に表示させるため DESC を指定します。
おお!期待通りの結果がでました。(^^)
JPQLって素敵な機能です!
次は調子にのって IN 式を使ってみます。
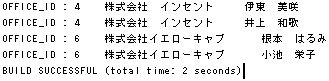
OFFICE_ID が 4 と 6 のタレントを検索してみます。
つまり、株式会社インセントと株式会社イエローキャブに所属しているタレントを検索します。
素晴らしい!
IN 式も完璧に使えます。(当然か・・・)
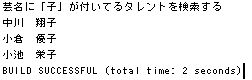
では LIKE 式はどうでしょう?
芸名に 「 子 」 がつくタレントを検索してみます。
これも間違いなく使えます。
次は COUNT 関数を試してみます。
データベースに登録されているタレントが何人いるか調べてみます。
登録されているタレントは8人です。
少ないと思うでしょうがこれ以上データ集めるのはつらくなってきたのでこれで遊んでます。
次は平均値を取得するための AVG 関数を試してみます。
登録されているタレントのバストの平均値を求めます。
出力された値が正しいかどうかは確認してません。
とりあえず、たぶん、問題なさそうです。
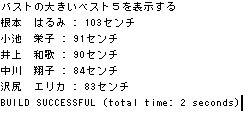
今度は登録されているタレントのバストのベスト5を調べてみます。
setFirstResult(int arg0) メソッドと setMaxResults(int arg0) メソッドを使いバストが大きい順に5人表示させます。
指定したとおりバストが大きい順に5人表示されてます。
ここでちょっと考えてみました。
もし5人目と6人目のサイズが等しかったとしたらどうだろう?
そこで指定を変更してみます。
setMaxResults(int arg0) メソッドのパラメータ値を5に変更し6人目まで表示させてみました。
どうやら沢尻 エリカさんと伊東 美咲さんが83センチと同じでした。
どのような仕組みで沢尻 エリカさんが上になるかは解りませんが注意が必要かも。。。
では MAX 関数を使ってみます。
サブクエリも使って一番大きなバストのタレントを検索してみます。
根本 はるみさんの巨大なバスト 103センチがちゃんと検索されてますね。
肩こるだろうなぁ・・・ (余計な御世話でした)
次はテーブルの結合を試してみます。
タレントIDが1のタレントの趣味を検索してみます。
パス式によるテーブルの結合を試します。
ちゃんと検索され表示されてます。
ここで面白いのは返される型が Object 型の配列だということです。
SELECT 節に永続フィールドをカンマで区切って複数記述した場合、各カラムの値は Object 型配列となります。
さて、このような検索条件にヒットするのが1件の場合はこれでいいのですが複数件ヒットする場合はどうでしょう?
今度は IN 式を使ってタレントIDが2,5,7のタレントの趣味を検索し表示させてみます。
今度もちゃんと検索され表示されてます。
しかし今度は複数件ヒットしているため Object 型配列のリストとして返されてます。
このあたりは注意しなければいけませんね。
このように Object 型配列、または Object 型配列のリストとして受け取ってしまうと配列内の各要素をキャストする必要が生じます。
これをスマートな方法で回避するにはコンストラクタ式という方法があります。
Java を知っている人には馴染みやすい方法です。
しかし、JavaBeans クラスを作らなくてはいけません。
面倒です!
ここまでやるならネイティブクエリと結果セットマッピングセットを使うのがいいかもしれません。
というわけでコンストラクタ式は省略です。(^^;
パス式のテーブル結合は識別子を使っているので Java を知っている人には馴染みやすいかも。
次は内部結合について調べてみます。
JPQLでの内部結合は、SQLにおける内部結合と同じです。
FROM 節に JOIN 演算子を使って結合します。
下記コードでは INNER JOIN と記述してますが JOIN だけでもOKです。
よって、このように想像どおりの結果となります。
さて、今度は外部結合について調べてみましょう。
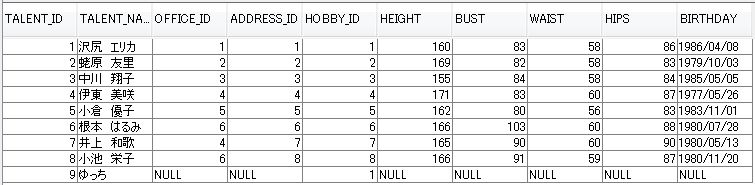
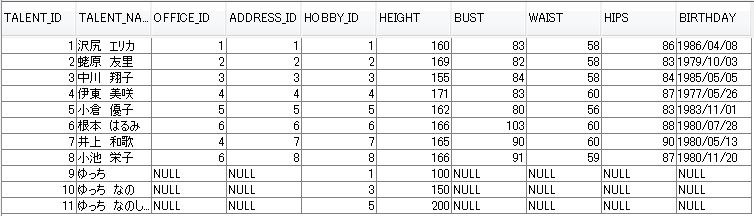
下図のようなデータがはいってるテーブルを使います。
talent テーブル
office テーブル
JPQLでは左外部結合だけしかサポートしていません。
将来的には右外部結合もサポートされるかもしれませんが現在は左外部結合だけです。
JPQLでの外部結合もSQLにおける外部結合と同じです。
関連を持っているエンティティオブジェクトだけでなく、関連を持ってないエンティティオブジェクトも抽出します。
結果は想像どおりSQLと同じようになりました。
左に記述された talent エンティティクラスを基準とし、右の office エンティティクラスと関連のないものまで抽出されてます。
タレントID 9 の ゆっちがまさにそれですね。
次は office エンティティクラスを左に記述してみます。
結果は上がさっきので下が office エンティティクラスを左に記述したものです。
今回はタレントID 9 のゆっちが抽出されてません。
基準となる、エンティティクラスが入れ替わったからですね。
次はちょっと特殊な結合を試してみます。
フェッチジョインです。
これは今までの結合と同じようなものですがちょっと変わってます。
何が変わっているかというと SELECT 節中にエンティティクラスを一つしか指定できません。
フェッチジョインでは下記コードを見るとわかるように FROM 節に JOIN FETCH と記述します。
そしてその左側に受け取りたいエンティティクラスを記述します。
右には左のエンティティクラスがリレーションシップを保持しているフィールド名を記述します。
さて、下記のようなコードが実行されるとどうなるでしょうか?
JPAエンジンによって内部結合したSQL文が発行されます。
そして二つのテーブルの全カラムがメモリに読み込まれます。
では、プログラムの実行結果を確認します。
内部結合と同じ結果が出てます。
フェッチジョインによって二つのテーブルの全カラムを読み込むことが可能です。
しかし、受け取るのは片方のエンティティオブジェクトだけです。
片方のエンティティオブジェクトだけを受け取るには必要ないが関連するエンティティオブジェクトを同時に取得したい場合には有効な手段のようです。
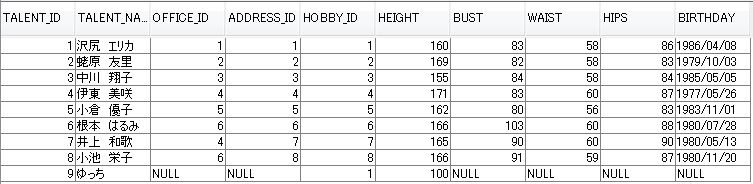
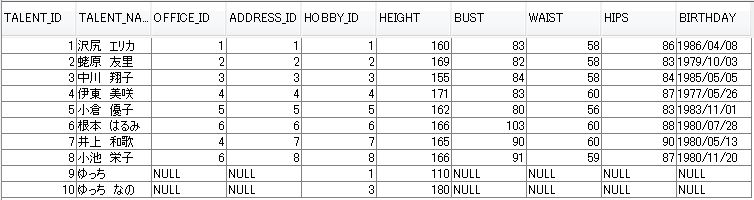
次は下図のテーブルを使用してバルク更新を試してみます。
タレントID 9 の HEIGHT カラムの値を 10 増やしてバルク更新してみます。
executeUpdate() メソッドでヒットした件数を int 型で取得します。
結果は当然一件です。
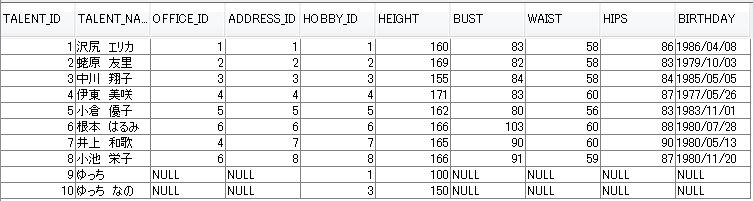
では、同じようにバルク更新を行います。
下記のテーブルを使用します。
タレントID 10 ゆっち なの の HEIGHT カラムの値を 変更してみます。
今回はトランザクションを開始してから find メソッドによりエンティティオブジェクトを取得。
そしてバルク更新によって HEIGHT カラムの値を 10 増やします。
そしてエンティティオブジェクトの HEIGHT カラム値をさらに 30 増やします。
そしてコミットしてトランザクションを終了します。
さて、どうなるでしょうか?
最初の HEIGHT カラム値は 150 だから 190 になるはずです。
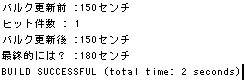
下の実行結果では なんと!
バルク更新前 HEIGHT カラムの値は 150
バルク更新ヒット数 1
バルク更新後 HEIGHT カラムの値は 150
トランザクション コミット後の HEIGHT のカラム値は 180
期待を裏切る結果ですね
期待どおりに HEIGHT カラム値が 190 になりませんでした。
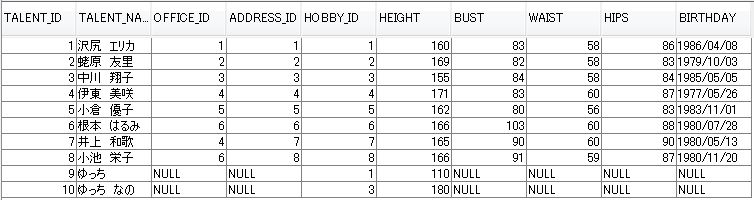
データベースの値も確認してみましょう。
やはり HEIGHT カラム値は 180 です。
このように同一のトランザクション内でエンティティオブジェクトの操作とバルク操作をするといけません。
何故かというとメモリ上に存在する永続化コンテキスト内のエンティティオブジェクトと同期が取れなくなるからです。
同一トランザクションン内でバルク操作とエンティティオブジェクトを使う場合はエンティティオブジェクトを取得する前にバルク操作を行うようにしましょう。
バルク削除も試してみます。
タレントID 11 のローをバルク削除します。
これも問題ないようですね。
EJB3.0 から一括して更新、削除ができるようになり便利になりましたね。
前はエンティティクラスのインスタンスを一つづつ取得して更新や削除をしなくてはいけなかったのにね。
こういった楽ができる新機能は歓迎です。
いちおう、ちゃんと削除されているか確認します。
タレントID 11 のローが奇麗さっぱりなくなってます。(^^)
次はネイティブクエリを試します。
これは使用しているデータベース専用のSQL文を発行できるものです。
どうして必要かというと使用しているデータベース専用にチューニングされたSQL文を発行することによってパフォーマンスを良くすることが可能になります。
それでは手始めにタレントID 2 のタレントの芸名を検索します。
createNativeQuery(String arg0) メソッドの引数を見ると今までとは違うことがわかります。
ネイティブクエリでもパラメータを使用できます。
位置を指定してパラメータをセットしているのが確認できますよね。
注意しなければいけないのがネイティブクエリではパラメータを名前で指定する方法は使えません!
まぎらわしいのでJPQLでも名前で指定できなくすればいいと思うのは私だけでしょうか?
では実行結果を確認しましょう。
ちゃんと検索されてます。
ただし、Object 型として返されてます。
複数件ヒットする場合は Object 型のリストとなります。
次はタレントID 2 のタレントの芸名とバストを検索します。
さっきのは検索するカラムが一つでしたが今回は二つです。
さて、どうなるでしょう?
今回もちゃんと検索できてます。
今回のように SELECT 節でカラムをカンマで区切って複数記述した場合、java.util.Vector オブジェクトの要素に格納されて返されます。
つまり単一の Vector オブジェクトか Vector オブジェクトのリストとして返されます。
次はちょっと面倒なネイティブクエリを試してみます。
結果セットマッピングを利用します。
カラムを複数記述するケースでは便利な方法らしいです。
でも、かなり面倒・・・
これはネイティブクエリの実行結果を任意のエンティティクラスにマッピングして受け取ったり、スカラ値で受け取るために必要なものです。
それではエンティティクラスを作ります。
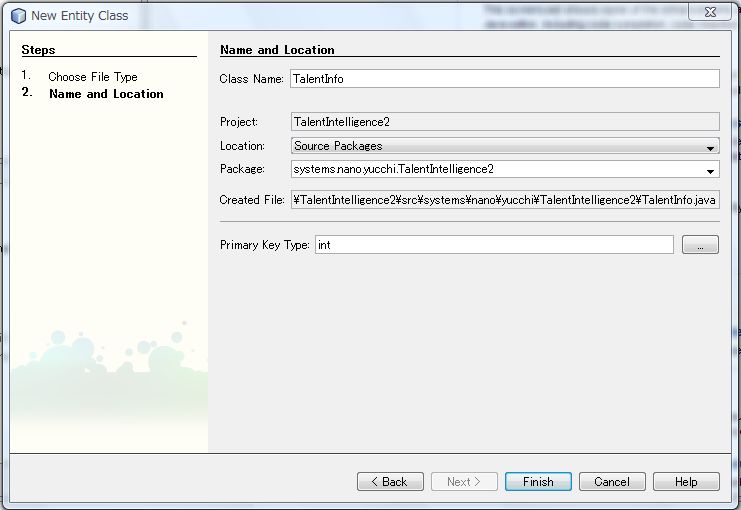
[ TalentIntelligence2 ] → [ New ] → [ Entity Class ] をクリックします。
New Entity Class ウィンドウを下図のように設定します。
[ Finish ] ボタンをクリックしまs。
エンティティクラスが自動生成されます。
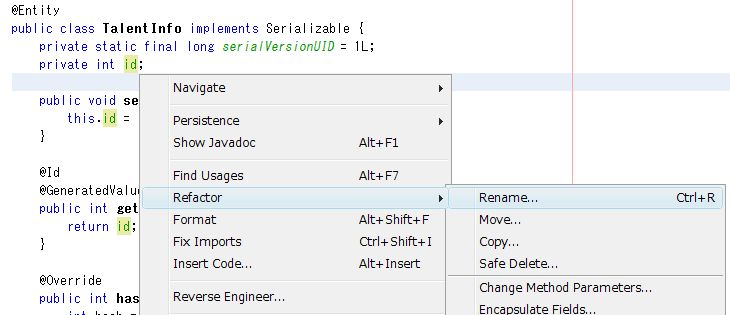
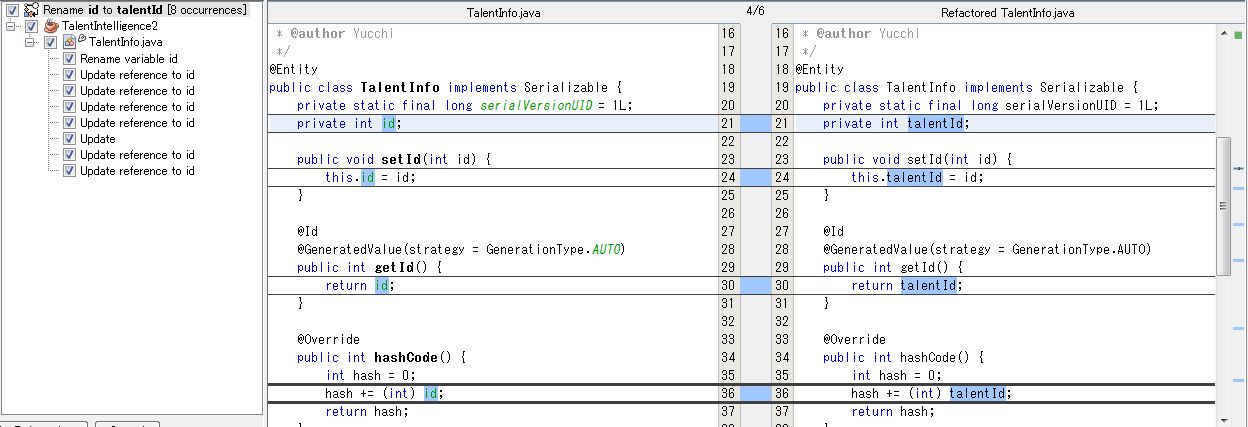
必要に応じて変数の名前を変更します。
[ Refactor ] → [ Rename... ] をクリックします。
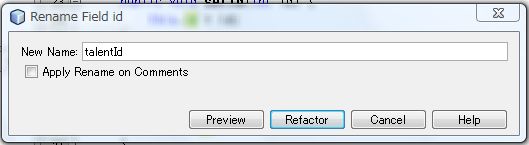
Rename ウィンドウが出ますので新しい名前を設定し、[ Preview ] ボタンをクリックします。
確認画面がでますので問題なければ [ Do Refactoring ] ボタンをクリックします。
同様の操作で Controller2 クラスからアクセスできるようにします。
次に、下記のように結果セットマッピング情報を記述します。
@SqlResultSetMapping はネイティブクエリの実行結果のマッピングを指定するために用います。
複数指定する場合は @SqlResultSetMappings を用います。
name 属性に結果セットマッピングの名前。ネイティブクエリのメソッド呼び出しで参照されます。
つまり、createNativeQuery メソッドの第二引数に指定した結果セットマッピング名になります。
entities 属性にはエンティティクラスへの結果セットマッピング
columns 属性はスカラ値への結果セットマッピングです。
もう少し詳しく見てみましょう。
entities 属性には、@EntityResult の配列を指定してます。
@EntityResult では entityClass 属性にカラム値を格納するためのエンティティクラスを指定してます。
fields 属性には、@FieldResult の配列を指定します。
それぞれの @FieldResult には entityClass 属性に指定したエンティティクラスの永続フィールド名( name 属性)とカラム名(column 属性)のマッピングを指定します。
このように面倒な手作業によるマッピングをすることによって、ネイティブクエリで指定したカラム値をエンティティクラス(TalentInfo クラス)のフィールドに格納した形で受け取ることができます。
ネイティブクエリの SELECT 節には記述するがエンティティクラスに格納する必要がなくスカラ値で取り出したい場合はどうするのでしょうか?
その場合、columns 属性を利用します。
columns 属性に @ColumnResult の配列を指定します。
@ColumnResult の name 属性にスカラ値として取り出したいカラム名を指定します。
これで結果セットマッピング情報の記述は終りです。
さて、このネイティブクエリはどのような型でかえされるのでしょうか?
スカラ値として取り出す必要がないなら columns 属性は不要です。
つまり、entityClass 属性に指定したクラスの型で受け取ることができます。
下記コードのようにスカラ値で取り出す必要がある場合、Object 型配列で返されます。
さて、このエンティティクラスの作成を進めましょう。
変数を記述します。
コンストラクタを作ります。
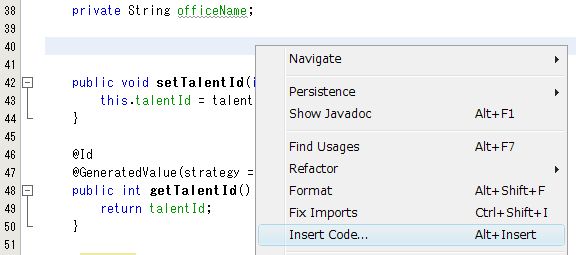
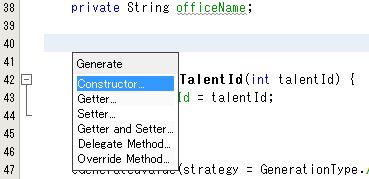
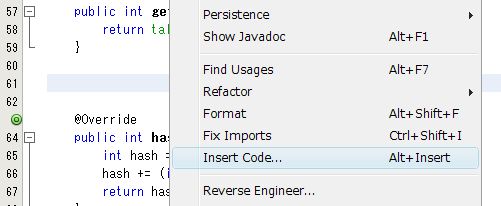
エディタでコンストラクタと入れたい所で右クリックして、[ Insert Code... ] をクリックします。
Constructor... をクリックします。
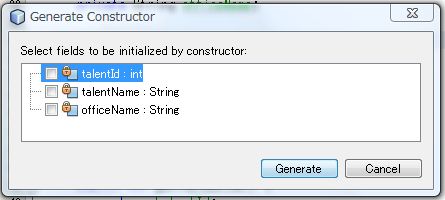
まず、空のコンストラクタを作るのでこのまま [ Generate ] ボタンをクリックします。
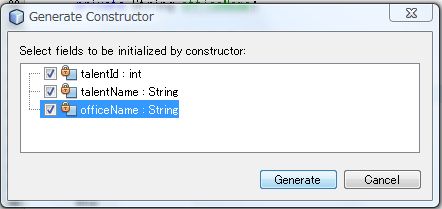
同様に引数に渡したいものにチェックをいれてコンストラクタを作成します。
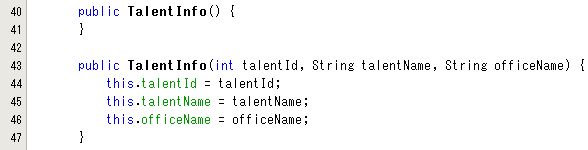
ちゃんと作成されました。
NetBeans を使うとこういった楽もできます。
タイプミスの心配もないのでうれしいです。
アクセッサメソッドも自動生成してくれます。
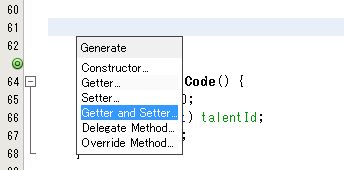
[ Insert Code... ] をクリックします。
[ Getter and Setter... ] をクリックします。
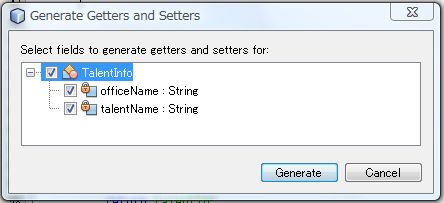
作りたいものにチェックを入れて [ Generate ] ボタンをクリックします。
これも奇麗に自動生成されてます。
機械的なアクセッサメソッドの記述をしなくていいですね。
では、結果セットマッピングを利用するネイティブクエリを試してみましょう。
タレントID 3 の TALENT_ID , TALENT_NAME , OFFICE_NAME , BUST , ADDRESS を抽出します。
Object 型の配列として返されてます。
objs[0] には TalentInfo クラスのオブジェクトが格納されてます。
objs[1] には BUST のカラム値
objs[2] には ADDRESS のカラム値
結果はちゃんと出ているがこんな複雑なことはしたくないってのが本音です。(^^;
JPAにはまだまだいろんな機能があります。
簡単に試せる範囲で遊んでみましたがけっこういいですね。
この先どうなっていくのか楽しみです。
もっと試してみたいことがあるが時間がないので先送りです(^^;